In a recent conversation with two executives from reputable manufacturing firms, I was fascinated to discover that their investment and effort in adopting AI were quite similar, but their business outcomes were distinct and diametrically opposite. In a cursory yet compelling fashion, one of McKinsey’s reports illustrates this divergence pointing out two types of firms in AI adoption: leaders who integrate AI quickly and laggards who struggle to scale up, resulting in a vast gap between them. Additionally, the report highlights that 63% of companies aim to invest more than 5% of their digital budget in AI, making it imperative for laggards to find ways to adopt AI at scale and generate ROI.
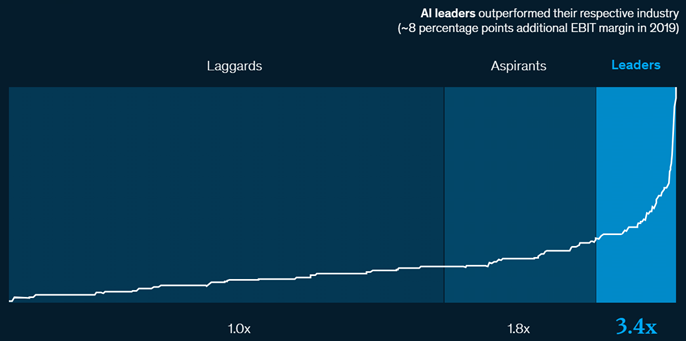
Figure 1 Source: McKinsey
While I could hypothesize the reasons for divergence between leaders and laggards, I felt the need to validate it. Based on peripheral research, it can be concluded that the gap between leaders and laggards in AI adoption is due to a) misalignment of AI strategy with business outcomes and b) inadequate management of AI risks during execution.
This article focuses on “inadequate management of AI risks,”, leaving the other reason for a future article.
What are the “AI risks” that need to be addressed?
McKinsey has brilliantly illustrated the “AI risks” and how companies are addressing them in the below picture.
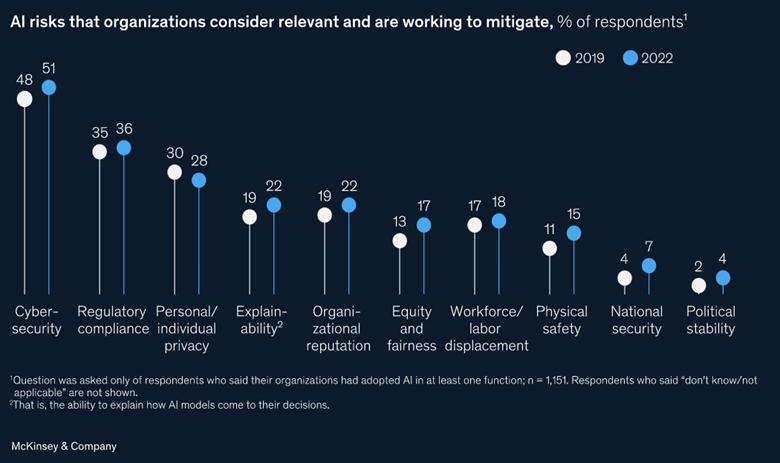
In the remainder of the article, I will concentrate on the subset of risks that AI execution teams can control and examine specific techniques and programming modules to alleviate those risks. Such, AI risks can be categorized under Privacy, Accountability, Security, Transparency, Explainability and Debias – an acronym I coined – PASTED. Companies that prioritize addressing these categories in their AI execution plans are more likely to achieve significant success:
Privacy: AI can collect, process, and analyze personal data that can be used to invade individuals’ privacy.
Accountability: AI decisions may not always be explainable, which can lead to challenges in assigning responsibility for negative outcomes.
Security: AI systems can be vulnerable to attacks, hacking, and data breaches.
Transparency: AI systems can be opaque, making it difficult to understand how decisions are being made and why.
Explainability: AI systems may not be able to provide explanations for their decisions, which can lead to mistrust and a lack of adoption.
De-bias: AI systems can perpetuate and amplify existing biases, which can lead to unfair and discriminatory outcomes.
How to address the “AI risks” at the operational and execution level?
Privacy
Some techniques for achieving reasonable privacy are:
- Data protection: Use techniques such as encryption, anonymization, and differential privacy to protect sensitive information. Python libraries like PyCryptodome and Cryptography can be used for encryption.
- Consent management: Develop clear policies and procedures to obtain and manage user consent for the collection and use of personal data. Python web frameworks like Flask or Django can be used to build consent management systems.
- Purpose limitation: Enforce purpose limitation policies that limit the collection, use, and disclosure of personal data to specific purposes. Use Python libraries like PyDatalog to create rule-based systems.
- User control: Provide users with control over their personal data using user control interfaces built using Python web frameworks like Flask or Django.
- Auditability: Audit and track the use of personal data within AI systems using Python logging libraries like Loguru or Python’s built-in logging module. Use methods such as logging, access controls, data tracing, and anomaly detection.
- Privacy design: Incorporate privacy into AI system design using libraries like TensorFlow Privacy or PySyft. Use methods such as differential privacy, federated learning, multi-party computation, and homomorphic encryption.
Accountability
Some techniques for achieving reasonable accountability are:
- Data logging: Keep a log of data inputs, outputs, predictions, and decisions to achieve accountability in AI models. Python’s built-in logging module can be used to create logs.
- Model interpretation: Use model interpretation techniques like SHAP or LIME in Python to explain model decisions and achieve accountability.
- Performance monitoring: Continuously evaluate AI model performance with Python libraries like Aequitas or Fairlearn to identify potential errors or biases.
- Authentication and access control: Verify user identity and restrict access to sensitive data and AI models with authentication and access control mechanisms. Python libraries like Flask-HTTPAuth or Django’s built-in authentication system can be used.
Security
Some techniques for achieving reasonable security are:
- Secure communication: Use SSL/TLS to encrypt data transmitted between AI systems and other systems or users. Python libraries like OpenSSL or Cryptography can be used for this.
- Secure storage: Encrypt and store sensitive data and AI models in secure locations using libraries like PyCryptodome or Cryptography.
- Regular security audits: Automate security audits using Python tools like Bandit, PyUp Safety, or Safety DB to identify vulnerabilities and risks in AI systems.
- Threat modeling: Use Python libraries like PyTM to perform threat modeling, identify potential security threats, and prioritize security measures accordingly.
Transparency
Some techniques for achieving reasonable transparency are:
- Model interpretation: Use SHAP or LIME to understand how the model is making decisions. Python libraries such as SHAP and Lime can be used for this purpose.
- Data visualization: Create visual representations of the data and model output using Python libraries like Matplotlib and Seaborn to help users understand how the model is working.
- Data lineage tracking: Keep track of where the data came from and how it was processed throughout the model pipeline using Python libraries like DVC and Pachyderm.
- Code auditing: Ensure that the code used to build the model is transparent and well-documented using Python libraries like Flake8 and Pylint.
Explainability
Some techniques for achieving reasonable explainability are:
- Local Interpretable Model-agnostic Explanations (LIME): A model-agnostic method for explaining the predictions of any machine learning model approximating it with an interpretable model. Python libraries like lime and interpret can be used to implement LIME.
- SHapley Additive exPlanations (SHAP): A model-agnostic method that computes the contribution of each feature to the predicted outcome. Python libraries like shap and interpret can be used to implement SHAP.
- Partial Dependence Plots (PDP): A model-specific method that shows how the predicted outcome changes with the variation in a specific feature while keeping all other features constant. Python libraries like pdpbox and sklearn can be used to implement PDP.
- Individual Conditional Expectation (ICE): A model-specific method that shows how the predicted outcome changes with the variation in a specific feature for an individual instance.Python libraries like pdpbox and sklearn can be used to implement ICE.
- Global Surrogate Models: A model-specific method that approximates the behavior of a complex model with a simpler and more interpretable model. Python libraries like interpret and skater can be used to implement Global Surrogate Models.
De-bias
Some techniques for achieving reasonable debias are:
- Fairness constraints: These are constraints applied during the training process to ensure that the model does not discriminate against certain groups. Python libraries like Fairlearn can be used to apply fairness constraints to your models.
- Dataset augmentation: Augmenting the training dataset with additional data that represents underrepresented groups can improve the model’s performance on those groups. Python libraries like Augmentor can be used for dataset augmentation.
- Algorithmic adjustments: Adjusting the algorithms used in the model to reduce bias can improve the fairness of the model. Python libraries like AIF360 provide algorithms for debiasing data and models.
- Bias mitigation techniques: These techniques aim to reduce bias in the data used to train the model. Python libraries like IBM’s AI Fairness 360 can be used to mitigate bias in data.
- Post-processing techniques: These are techniques applied to the output of the model to remove or reduce bias. Python libraries like Themis and Aequitas provide post-processing techniques for debiasing.
Conclusion
If organizations fail to manage AI risks effectively and without a firm commitment at all organizational levels, they risk being stuck in AI proof-of-concept purgatory. This can prevent them from applying AI to complex and high-value problems, which ultimately leads to wasted investments and a lack of significant and sustainable ROI. The situation is similar for AI specialized firms selling software in the market. An AI offering that covers the PASTED risks is more likely to win with adoption and scale, even if a competing alternative claims to have a superior AI model.
References